
CAPTCHAs – these things:

A human creation built to foil robots. However, as is ever so common these days, the robots are winning. But! it doesn’t have to be that way.
The first CAPTCHAs were created in 2000, and most every CAPTCHA since has remained virtually the same. This becomes problematic when thinking about CAPTCHAs in the context of being security applications (which they largely are). The reason for this is that typically in security, having a security application that has not been updated in 17 years is frowned upon because it means the entire world of attackers has had 17 years to throw new technology at breaking your old technology. With that said, what has happened in the past 17 years that's affected CAPTCHAs? The overarching answer to this is Machine Learning has become mainstream. Things like Neural Networks have gone from cutting-edge research technology used by the fringes of computer science to something bored teens can play with on the weekends. What is beautiful about neural networks and similar technologies is that they are oftentimes far less complex than alternatives for a programmer. What would previously require thousands of lines of code can now be done is a simple hundred or so. Those of you who have never used neural networks may find the above statement rather curious. What I mean by saying that using a neural network is a more simple way to complete complex tasks. I’ll use the example of having a computer learn to recognize a picture of a bike. To have a computer recognize a picture of, for example, a bike without a neural network (the ‘classical’ way), one would code in specific features of a bike.

Source: http://www.ilovebicycling.com/ For example, one could tell the program to look for two circles of black with silver in the middle connected by a line. To do this, the program would likely break the image into simple shapes like lines, circles, ellipses, etc. This works but only for a side profile of a bike. What if the bike is on it’s side or hung upside down or it’s a head on view? A programmer would be forced to write new rules for each possible view and have the program do the required computation to check against each rule. This method is computationally cheap to train (There is no real training aside from the pre-written rules.) but computationally expensive to check each image and expensive to have a programmer write rules. This makes the idea of having a company that writes an algorithm and sell CAPTCHA Solving as a service economically difficult because it would require lots of processing power and even more skilled labor to write algorithms for each CAPTCHA. This costs more than most are willing to pay and costs more than the the alternative (paying people in poor countries to solve CAPTCHAs by hand). Let's discuss how a computer can recognize a picture of a bike with a neural network. In the context of classification problems, a neural network is an algorithm that takes in many data points and a result, say, for example written characters and what number they are. The neural network would look at 1,000 7’s as black white grids and weigh their points, so if in 7’s a pixel (x,y) is black in 90% of pictures of 7’s, then it’s weight would be 0.9. The neural network takes all the points in the image and weighs them. It then writes a table of pixels and weights. When the program is asked to classify an image it has never seen, it would look up each pixel value against the table of 1’s, 2’s, 3’s, etc and see which set of weights it best matches and from that, one knows how sure the program is of the image it receives being each letter it was trained against. Now, let's take this back to the bike example and how we would use neural networks. If one applies a similar process to the bike example using a thousand images of bikes, the column of weights would resemble the full rule that define what a bike looks like from all angles. These methods are extremely effective for Optical Character Recognition. In recent years, Google has been able to (in less than 100 lines of python) recognize handwritten digits with 99.2% effectiveness. This fixes all of the issues that previously rendered CAPTCHA solving as a service through software economically impractical. We have seen technology similar to Neural Networks used to break CAPTCHAs. In a paper entitled “A Low-cost Attack on a Microsoft CAPTCHA,” researchers from Newcastle University achieved a solving rate per CAPTCHA of between 100% and 95%.
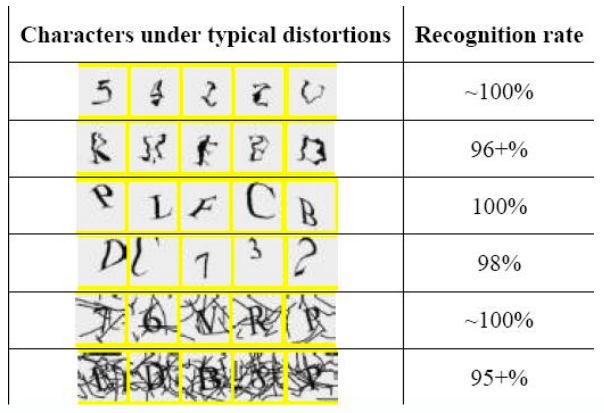
Source: http://www.zdnet.com/article/microsofts-captcha-successfully-broken/ As it stands, we are only hearing about breakthroughs coming from the academic world. It is not unreasonable to think that the blackhat world has been pioneering breaking CAPTCHAs. As time goes on, these attacks will become cheaper and cheaper, and far more common. With all that said, what is the blue team to do? In this context, the blue team's job should be two things. 1. Building and implementing CAPTCHAs that are more computationally expensive to solve. The key in this is ‘more expensive.’ The reason I say this is because if the blue team acts as if their CAPTCHA cannot be beat, that leads to problems like not updating the CAPTCHA in 17 years. 2. The blue team should try it’s best to avoid relying on purely using task-solving CAPTCHAs to fight spam. One solution that embodies both of these things well is Google’s reCAPTCHA. What the end user sees when they interact with Google’s reCAPTCHA is a checkbox that says “I am not a robot.” When the user checks the box, the CAPTCHA looks at a myriad of details that Google does not extensively specify. As an example, I’ll list some details that are theorized to be taken into account:
- The path the user's mouse took to get to the check box.
- Details of the user's browser.
- How much time the user spend filling out the form.
- IP reputation.
Lastly and most importantly, reCAPTCHA (allegedly) looks at trends across all sites that use reCAPTCHA and other details it can glean about user behavior as a whole. If after checking the box, the user is determined legitimate by reCAPTCHA, a checkmark is displayed and the user is sent on their way. If reCAPTCHA finds the user as illegitimate, the user is served a full color image classification problem. i.e.

The advantage a CAPTCHA like this has over a traditional CAPTCHA is that is is far more difficult to get access to a training dataset of say street signs than it is to generate a training set of letters. Google uses proprietary datasets to generate these CAPTCHAs. To beat a CAPTCHA like reCAPTCHA, an attacker has to be on par with Google in having large datasets. This simple fact is what makes Google’s reCAPTCHA great. Now, if you as a blue team want to implement your own solutions and don’t want to use reCAPTCHA, what can you do? (Disclaimer: These are just ideas that I have after doing research; they are not guaranteed to be right for you.) Let's go back to the two things you want to achieve. 1. You want to make solving your CAPTCHA as computationally expensive as possible. Perhaps the best way to do this without having access to proprietary datasets nobody else has is to use three dimensional CAPTCHAs. The reason for this is that OCR is no longer difficult nor expensive for a computer to solve. When we add in three dimensional math, this becomes more expensive both computationally and memory-wise.
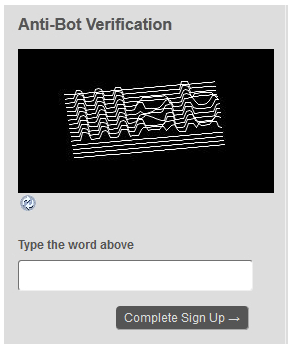
The reason that a CAPTCHA like this is more computationally expensive is because it requires some guess-and-check from the solver as to what angle the image is being viewed from. Additionally, it requires 3-dimensional math, which is expensive computationally. This is not impossible to solve, but it is harder and would likely require a GPU to be solved efficiently. Forcing an attacker to rent servers with GPUs makes hosting solving infrastructure more expensive. This type of three dimensional CAPTCHA could be made even more difficult to solve with the addition of greater visual noise and random change of depth that varies throughout. The other thing CAPTCHAs don’t do that they should is use a multitude of fonts. CAPTCHAs are (mostly) just renderings of fonts and noise. What this allows an attacker to do is roughly reverse engineer your CAPTCHA and create a dataset with which they can train a machine learning model. If you use many fonts randomly, this requires an attacker to train their model against every font you use. This makes training and solving many times more expensive. Lastly, distortions of the letters would add to the complexity of solving such a CAPTCHA because it adds random error, which would require an attacker to have a significantly larger sample size against which to train a neural network. 2. The blue team should try it’s best to avoid relying on purely using task solving CAPTCHAs to fight spam. This includes things like looking at IP reputation; blocking proxies and Tor exit nodes; implementing rate limiting by IP; monitoring traffic; looking at what normal browsing patterns are and scrutinizing IPs that regularly defy these patterns; and looking at headers and trying to fingerprint browsers that seem out of the ordinary. If you only take one thing away from this, take this: If you only use a common 2-dimensional text-based CAPTCHA to prevent spam, you’re doing it wrong. If you only use something like Google’s reCAPTCHA, you’re doing it well but not as well as you could be doing. What you really want to have is a great CAPTCHA, like reCAPTCHA or a proprietary method, as well as build infrastructure to monitor traffic and traffic trends. You can’t always fully beat spam, but you can make it more expensive to an attacker.
About the Author: Nick McKenna is a student researcher who has had an interest in cyber security for the past five years. Nick likes seeing how things work and trying to break them. If you have any questions, you can contact Nick here. Editor’s Note: The opinions expressed in this guest author article are solely those of the contributor, and do not necessarily reflect those of Tripwire, Inc.
Meet Fortra™ Your Cybersecurity Ally™
Fortra is creating a simpler, stronger, and more straightforward future for cybersecurity by offering a portfolio of integrated and scalable solutions. Learn more about how Fortra’s portfolio of solutions can benefit your business.

