
Last week, I presented a talk at OWASP's AppSec California titled "We All Know What You Did Last Summer," where I spoke on the topic of privacy, security and the "Internet of Things." My primary focus was not necessarily on the privacy and security of devices themselves, but more regarding the security implications of the data they generate. I used several criminal cases I have been involved with as examples, where fragments of digital trace evidence were used to develop rich profiles of criminals leading to conviction. These methods involve correlation and identifying patterns in seemingly disparate data points. The twist is that these same methods used to profile and track criminals can also be used by criminals to profile and track you. I view the "Internet of Things" not necessarily as "things" but as "sensors" being deployed into our lives. These sensor devices generate data as we interact with them and as they interact with other devices. This continuous process results in a cascading effect of data generation, providing increasingly rich data sets, which can be used to create profiles of us, our activities, our friends and even our personality. A recent study by EMC estimates that by 2020 the amount of data generated as a result of the Internet things will increase tenfold to nearly 44 Zettabytes annually (44 trillion GB) by 20201. The majority of the data does not reside on the devices themselves, but is stored and distributed through third-parties where data is aggregated. Although the majority of that data is generated from things like streaming video, there is still rich meta data that can be extracted from these interactions. As we interact with these sensors there are different stages of data creation. First, is the data we consciously create through email, tweets, SMS messages, phone calls, check-ins and other activities. Second is the data that gets created for us by others or automated processes, usually through transactions, posts and requests. In this cycle of data creation, there becomes a wealth of both direct and inferred data about you that is available in the form of analytics and other sources.
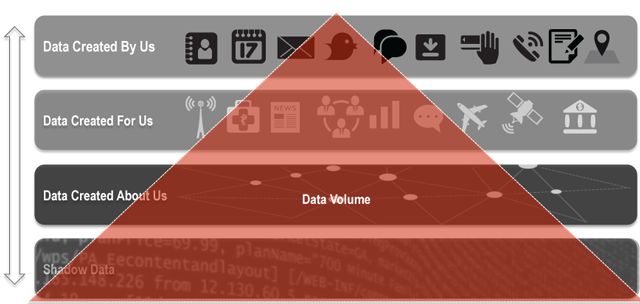
There is another type of data that is generated through this process that may not be used directly, but is also the most abundant—I call it "shadow data." This data lives in log files and other machine data, which may seem disparate and without any personally identifiable information directly; however, when connections are made to other data types, shadow data can reveal patterns. For example, a single SMS message will generate more than 20 log files/entries as it travels through multiple carriers' infrastructure. Although the original message may be deleted long ago by both parties, the trace evidence of that message lingers on for months, years and possibly forever depending on how that data is archived.
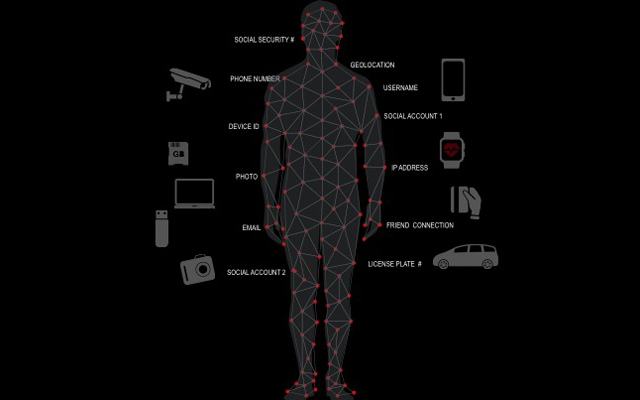
If we look at the rise of shadow data and pair it with machine learning, big data analytics tools and human mistakes, there is an increased likelihood of extracting meaning and previously unseen correlations in data. Everything and everybody has unique identifiers – be it a number or other descriptors. Sometimes they may not seem like they identify people, but with a few simple associations, making these connections becomes trivial. Device serial numbers, for example, once mapped to an individual reveals a great deal. When Apple released their iPhone, the device identifier (UDID) was used by advertisers and app developers to uniquely identify devices. The problem is that there was also a connection to user IDs leading to a number of privacy issues, allowing marketers and others with the ability to map behaviors and even location across application platforms. Apple took steps to fix this issue, but it took time and effort and the previous data generated still exists. We are even still seeing how agencies used data linked to the UDID in leaked Snowden documents. This same problem is being replicated amongst the Internet of Things, including laptops, cell phones, fitness trackers, or storage devices—every device we interact with, as well as every device our devices interact with, directly or wirelessly leaves a trail.
Case Study: Camera Serial Numbers
Several years ago. I developed a tool to help map images uploaded online to the cameras that took them simply by discovering that many cameras embed the serial number of the camera into an image's EXIF data. The tool was used to help recover stolen cameras, as well as to help track child pornographers by simply extracting the camera make, model, serial number and the URL of where the image was found. The utility helped police solve several crimes, all with only the serial number of a camera. One particular case tracked a stolen camera a year after it was stolen and after it had been sold twice – once on Craigslist and again on eBay.

Photographer John Heller, who I helped recover his $6K camera with the property receipt from the LAPD
Although you may not consider a professional camera a component of the "Internet of Things," the data these devices generate, or the fact that they are connected to devices makes them part of the ecosystem. Device IDs find themselves not just in images, but appear in log files and other "hidden" places many consumers would not think to look for identifying information.
Location, Location, Location
Of course, it isn't just serial numbers that we find in images and logs but also other types of data. One common piece of information is location, which can be identified by IP address to the city you live in to more granular fragments of data, such as the geo location embedded in images and check-ins with various social apps. I have tracked several dozen thieves using Wi-Fi location services along with other pieces of evidence, as well as extracting location data from images, log files and other sources. Many times, location data can be derived from other pieces of information, so even if you do not knowingly provide location data, it can still be determined, even when disabling geolocation on your phone or other devices.
I tracked a pair of criminals targeting various wireless stores in the Portland area, after they took photos of themselves which were backed up automatically to an encrypted backup service where I was also able to pull GPS coordinates. In the images I also saw a temporary trip permit which helped investigators even further. In this case the suspects were caught, along with four others involved in various crimes, they even recovered a stolen car.

Surveillance photos of one of our wireless store thieves in action Self incriminating selfies taken by the thieves with embedded timestamp and geolocation data

So, although I used the various pieces of data for tracking criminals, this same data exists for everyone. Criminals, hackers and marketers alike can leverage this data to learn more about you than you may think. If we add data breaches to the mix where hackers have access to more in-depth information, including credit card numbers, credit reports, medical information, phone/data backups and other sensitive data, we have an even more dangerous situation.
Securing the Infrastructure of Things
As we delve into the Internet of Things, where everything is connected, the advice I gave at AppSec this year, was for developers to stop blindly collecting data and only collect the data that you need and nothing more. If you need to store data, can it be encrypted and stored in such a way that not even you have access to it through the use of private keys? If so, do it.
In your risk models, make assumptions that your customers' data is compromised – what is the damage that it could cause? What information can be derived from this data? Can the data be overlayed with data from other publicly available sources or even other breaches to enrich the fidelity of individual profiles?
These are questions that are rarely asked when developing hardware and applications that we should be asking. The data you collect today may seem like it is innocuous but down the line, it could be harvested and correlated in ways you didn't imagine.
In addition to developers taking security and privacy into consideration when collecting data, companies need to take into consideration the security of the "infrastructure of things." Securing the end user endpoint is one thing, but as we have seen with a number of high-profile breaches over the past few years, the real target for hackers is the infrastructure that drives the Internet of Things. The complexity of securing these types of environments has unique challenges as many rely on cloud-based or virtual environments to provide elasticity as demand for services grow.
I will be discussing how organizations can better secure this type of infrastructure in future blog posts. If you are responsible for securing infrastructure like this, what unique challenges do you face that strays from "traditional IT"? Let us know in the comments, I would like to hear from those in the trenches.

