
Data classification can feel like an overwhelming task, especially for organizations without a strong practice in place. As with any security approach, data classification is both crucial and tempting to avoid. Regardless of whether the value is recognized, there’s a chance that it gets pushed further and further down the priority list in favor of items that are easier to address.
In this article, we’ll help you build a case for data classification and fill in some important knowledge gaps to ensure your approach is comprehensive. It will require resource investment - time, money, and staff, particularly - but will, in the long run, help organizations avoid costly mistakes.
What is Data Classification, and Why is it Important?
Data is the lifeblood of a modern organization. Your data is crucial for your business to thrive regardless of your industry or offering. As such, ensuring your data is secure and easily accessible to the right people is paramount.
At a basic level, data classification refers to organizing your data by categories to aid in accessing, using, leveraging, and securing it effectively. Proper classification makes your data easier to locate and retrieve when required. It is particularly relevant for risk management, compliance, and data security.
Data classification relies upon best practices for categorization using visual and metadata labels related to predefined criteria. Of course, you can’t classify what you don’t know. To start, you’ll need to focus on data discovery to assess the scope. Data lives in many places in today’s modern world, and it is all equally important. Ensure you’re looking at the endpoint, in databases, on network shares, and in the cloud.
Why is data classification important? Its need is driven by many factors, including governance, industry-specific regulatory requirements (such as HIPAA, GDPR, PCI, CCPA, and others), compliance, IP protection, or the simplification of your security strategy.
Why Data Classification is Foundational
Organizations generate massive amounts of data. Not only that but as cloud adoption and shifts in approaches to work (including hybrid and remote models) grow rapidly, the classification and protection of data take priority.
Recent reports found that over half of organizations have all their applicable infrastructure in the cloud, and nearly three-quarters of companies are hosting more than half of their workloads in the cloud. In 2021, cloud adoption - bolstered by the pandemic and shifts in ways of working - grew 25%.
In environments reliant upon cloud services, data is more available to end users and those who need it. Unfortunately, that also makes data more vulnerable to security threats. Well-designed data classification is vital to data security and governance, including data loss prevention (DLP), enterprise digital rights management (EDRM), and data access governance.
Bad actors target data for exploitation, including ransomware attacks. Phishing and ransomware attacks are a lucrative business, with damages expected to reach $20bln in 2022. With figures like that, it’s clear why organizations and security professionals are investing in data classification. In fact, a reported 72% of security decision-makers have their sights set on data classification implementation.
Data Classification Methods
When selecting a data classification, it is typically a matter of deciding which approach to start with. Each method offers insight into organizational data and can be combined to increase security and mitigate the risk of misclassification, whether unintentional or malicious.
Content-Based Classification inspects and interprets file data for sensitive information. This method includes regular expression and fingerprinting, answering the question, “What’s in this document?”
Context-Based Classification points to applications, locations, creators, or other variables that indicate sensitive information. This approach answers the questions, “How is this data being used?”, “Who is accessing it?”, “Where is this data being moved or transferred?” and “When is the data being accessed?”
User-Driven Classification relies upon end-user or otherwise manual selection based on user knowledge and discretion at the point of creation, editing, or review to identify sensitive data and documents. This method requires a well-defined workflow.
Gartner recommends that organizations use a collaborative approach to combine the above methods. Chief Data Officers (CDOs) should collaboratively define and use classification capabilities to identify, tag, and store all data. A combination of user-driven and automated classification will ensure coverage and reliability.
How to Implement Data Classification in Your Business
As you may imagine, a successful data classification strategy will affect - and rely upon - employees across your organization. Key players include:
CIO & CISO are responsible for all data protection and technical responsibility. It is crucial for both individuals to understand the sensitive data landscape.
Business User Leadership members will understand that data classification increases the visibility and protection of customer and product development data.
Data Creators and End Users should be highly aware of the need to protect data, including the risks and ramifications of data leaks.
Legal and Compliance players are particularly concerned with risks and should be kept abreast of the scope of sensitive data and measures to protect it.
Getting users involved early will support organizational success in data classification, particularly as it affects individuals’ workflow.
Define and Implement Your Policy
As mentioned above, developing and implementing a data classification policy can initially feel overwhelming. Thankfully, the entire process can be broken down into steps to help you (and your organization) see it as a manageable endeavor. The overlying theme to getting started is: start simply. That doesn’t mean simply “start,” but rather start with a simple approach and build from there.
The Digital Guardian (DG) Data Classification & Protection approach offers a data-centric plan comprised of a four-step framework:
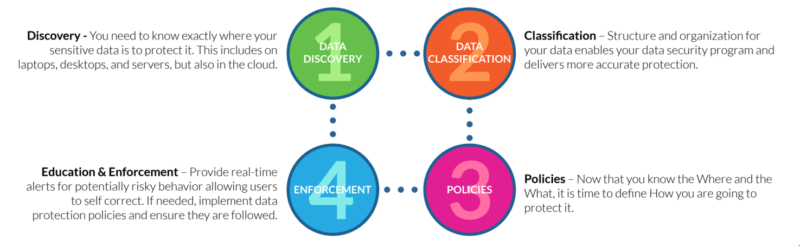
Through the DG Data Protection Plan, organizations can protect their valuable data pool from threats (both internal and outsider) by leveraging integration built-in automation while limiting false positives and false negatives.
Combining data discovery and classification, policies, and enforcement, Digital Guardian offers a comprehensive approach to content-, user-, and context-driven data protection.

About the Author: Having spent her career in various capacities and industries under the “high tech” umbrella, Stefanie Shank is passionate about the trends, challenges, solutions, and stories of existing and emerging technologies. A storyteller at heart, she considers herself one of the lucky ones: someone who gets to make a living doing what she loves.
Editor’s Note: The opinions expressed in this and other guest author articles are solely those of the contributor, and do not necessarily reflect those of Tripwire, Inc.
5 Things Your FIM Solution Should Be Doing for You
Discover the pivotal role of File Integrity Monitoring in maintaining system security and compliance with major standards. Tripwire Enterprise stands out as an advanced solution, offering real-time detection and detailed context for system changes, making it a superior choice for robust cybersecurity.

