
The past few weeks, I’ve been spending a lot of my free time preparing for the OSCP exam, which means refreshing a lot of skills that I haven’t used in years. A large part of that is rebuilding muscle memory around buffer overflows, so that’s how I spent my four-day weekend. I logged about 70 hours compiling small programs, writing buffer overflows, building simple ROP chains, and honestly having a lot of fun.
When I started doing this stuff, Python 2 reigned supreme. These days, Python 3 is more common on systems, but a lot of the materials out there still reference Python 2. One of the things I noticed as I hit a wall myself early in the weekend was that there’s a bit of trickiness involved in ensuring you get the data you want out of Python 3. It was something I came across naturally due to the way I ran my code and when I started Googling, I realized that there were a lot of questions and a few stack overflow responses, but that nobody really laid it out with a detailed explanation of what was going on. So, that’s what I’m going to do … walk you through a peculiarity of Python 2 vs. Python 3 code that may have you banging your head against the wall.
To start, we’ll use msfvenom to generate shellcode and look at the differences in interacting with it:
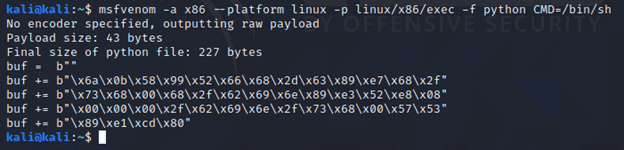
This code is then placed into a simple Python script, which we run with both Python 2 and Python 3:
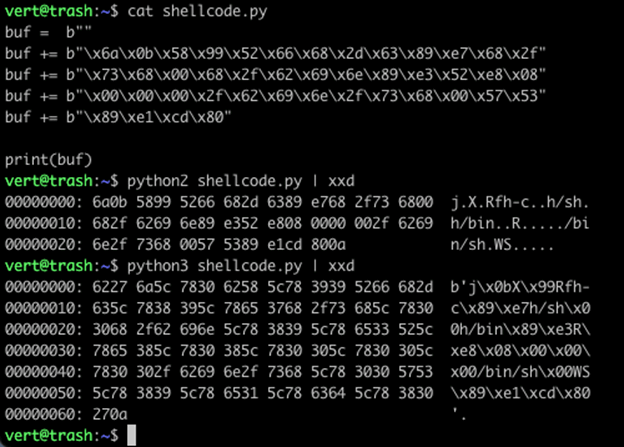
Notice the difference between the hex output on our print statement. We have that familiar b’ at the start of our sequence and the ‘ at the end before the 0x0a. Our sequence has been printed out as literal characters. Instead of 0x80 (in position 2A), we now have 0x5c 0x78 0x38 0x30 (in positions 0x5C through 5F). That is significant character expansion. This definitely isn’t going to work as shellcode.
Instead of print(), however, Python 3 has a different method of sending raw bytes to the screen. We can import sys and use sys.stdout.buffer.write().
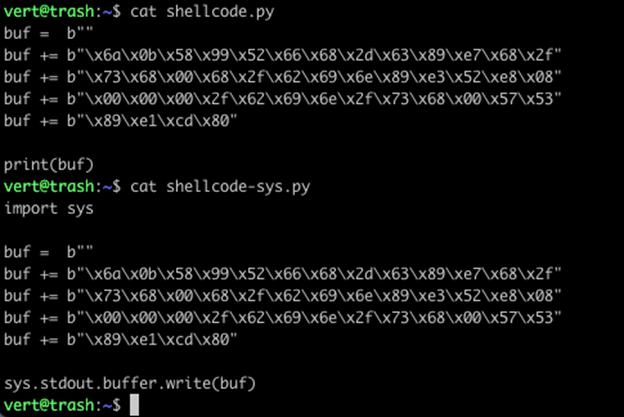
When you run these two files, you can see the improvement in the output already.
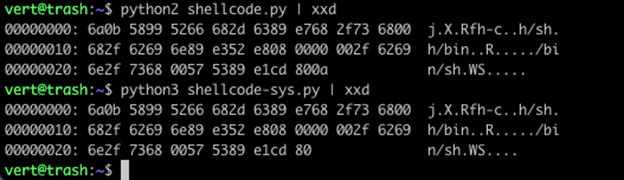
However, if you look at the two pieces of shellcode, you’ll notice that the Python 2 output is 1 byte longer. Our Python 3 output does not contain the 0x0a in position 0x2B.
The Python 2 print statement help says:
A "'\n'" character is written at the end, unless the "print" statement ends with a comma. This is the only action if the statement contains just the keyword "print".
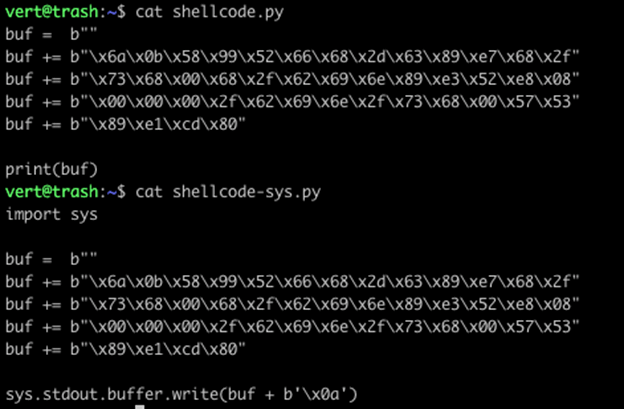
In order to replicate this functionality in Python 3, we need to append a single byte 0x0a to the end of our buffer.
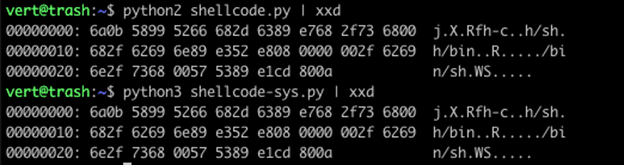
We now have identical output between our Python 2 shellcode and our Python 3 shellcode.
There is one additional approach you can take, which is to write the contents of your shellcode to a file. You can then work directly with that file.
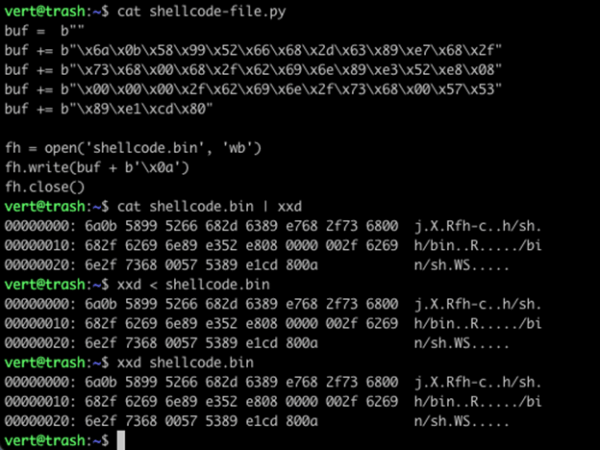
As I said, I noticed that a lot of people search for this, and I didn’t see a clear walkthrough, so hopefully, you found this useful.
Mastering Security Configuration Management
Master Security Configuration Management with Tripwire's guide on best practices. This resource explores SCM's role in modern cybersecurity, reducing the attack surface, and achieving compliance with regulations. Gain practical insights for using SCM effectively in various environments.

