
Word splitting is a function of BASH that I was unfamiliar with, but it is definitely one that impacted my recent research.
From the bash(1) man page:
IFS
The Internal Field Separator that is used for word splitting after expansion and to split lines into words with the read builtin command. The default value is <space><tab><newline>.
Word Splitting
The shell scans the results of parameter expansion, command substitution, and arithmetic expansion that did not occur within double quotes for word splitting.
The shell treats each character of IFS as a delimiter, and splits the results of the other expansions into words using these characters as field terminators. If IFS is unset, or its value is exactly <space><tab><newline>, the default, then sequences of <space>, <tab>, and <newline> at the beginning and end of the results of the previous expansions are ignored, and any sequence of IFS characters not at the beginning or end serves to delimit words. If IFS has a value other than the default, then sequences of the whitespace characters space and tab are ignored at the beginning and end of the word, as long as the whitespace character is in the value of IFS (an IFS whitespace character). Any character in IFS that is not IFS whitespace, along with any adjacent IFS whitespace characters, delimits a field. A sequence of IFS whitespace characters is also treated as a delimiter. If the value of IFS is null, no word splitting occurs.
Explicit null arguments ("" or '') are retained. Unquoted implicit null arguments, resulting from the expansion of parameters that have no values, are removed. If a parameter with no value is expanded within double quotes, a null argument results and is retained.
Note that if no expansion occurs, no splitting is performed.
A few additional notes from the bash(1) man page that may help:
Command Substitution
Command substitution allows the output of a command to replace the command name. There are two forms: $(command) or `command`
Bash performs the expansion by executing command and replacing the command substitution with the standard output of the command, with any trailing newlines deleted. Embedded newlines are not deleted, but they may be removed during word splitting
Process Substitution
Process substitution is supported on systems that support named pipes (FIFOs) or the /dev/fd method of naming open files. It takes the form of <(list) or >(list). The process list is run with its input or output connected to a FIFO or some file in /dev/fd. The name of this file is passed as an argument to the current command as the result of the expansion. If the >(list) form is used, writing to the file will provide input for list. If the <(list) form is used, the file passed as an argument should be read to obtain the output of list.
When available, process substitution is performed simultaneously with parameter and variable expansion, command substitution, and arithmetic expansion.
Expansion
Expansion is performed on the command line after it has been split into words. There are seven kinds of expansion performed: brace expansion, tilde expansion, parameter and variable expansion, command substitution, arithmetic expansion, word splitting, and pathname expansion.
The order of expansions is: brace expansion; tilde expansion, parameter and variable expansion, arithmetic expansion, and command substitution (done in a left-to-right fashion); word splitting; and pathname expansion.
For this example, we’ll start with the same shellcode we used in the last VERT post, but we’ll then modify it to contain more characters that will be impacted by word splitting.
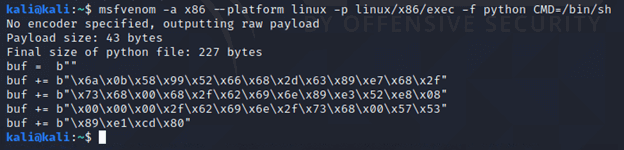
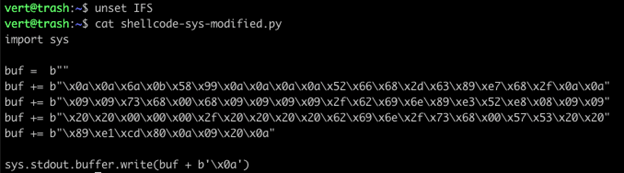
After generating the shellcode, I unset IFS and modified my shellcode file. I took the characters that IFS replaces – 0x0a (newline), 0x09 (tab), and 0x20 (space) – and embedded them within the buf variable. This is no longer viable shellcode, but I’m going to continue to refer to it as our shellcode.
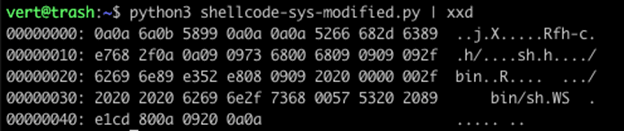
In our first example, we run Python and pipe the output into xxd. We can see that our shellcode appears the same as it does within the file.
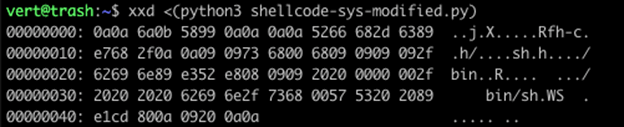
We can see here that we get the same output from process substitution. That is because word splitting is not performed on process substitution.

Note in the above example, which uses command substitution, that our output has suddenly changed.
- We have lost all of our 0x00.
- We have lost all of our 0x09.
- Where they did exist seems to have been replaced with a single 0x20.
- If we look at position 0x10 in the process expansion example, we see the following: 0xe7, 0x68, 0x2f, 0x0a, 0x0a, 0x09, 0x09, 0x73, 0x68.
- In the command expansion example, we can find that same 0xe7 in position 0x0B. It has the following order: 0xe7, 0x68, 0x2f, 0x20, 0x73, 0x68.
- The tabs (0x9) were replaced by a single space (0x20)
- All of our 0x0a instances have been removed except for the single 0x0a at the end of the content.
- All of our 0x20 instances have had duplicates removed.
Your first thought is probably, “But Tyler, you aren’t using the same commands!” You are 100% correct, I’m trying to show you how things change depending on the command you use and why this might, for example, impact the badchars filter you use in msfvenom.
To better understand the difference between those commands, let’s take a look at the same commands using grep.
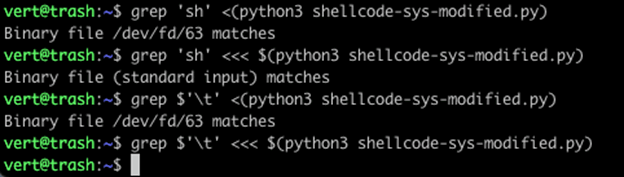
In the first command, we use process substitution. You can see grep performed it’s search on an anonymous pipe (/dev/fd/63). With command substitution, we’re using a here-string pass the data in from standard input. Here-strings are a way of saying, "Treat stdin like a file." Additionally, while we find the string ‘sh’ in both files, note that our tab (\t or 0x09) is absent from the command substitution
If you would like further explanation, consider the image below. Note that our here-string with command substitution above behaves the same as the piped Python output below. While our command substitution piped into grep and our command substitution as an argument to grep both produce errors while processing the binary output.
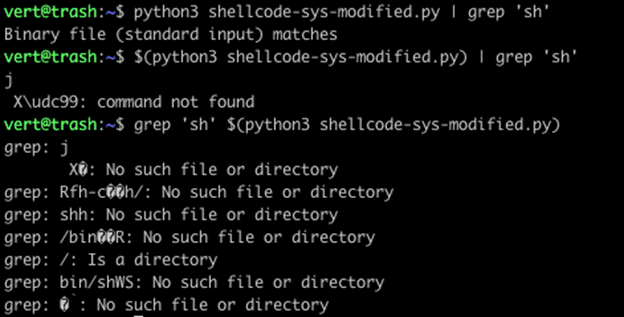
So far, all of this has been a complicated explanation of why you frequently use badchars to produce specific shellcode and how different methods of command execution may produce unexpected output. However, it gets a little trickier because of that IFS variable we referenced at the start. Remember that I unset it. Let’s take a look at what happens as we change the value of IFS. We’ll specifically look at the here-string command substitution that has seen the most change during use.
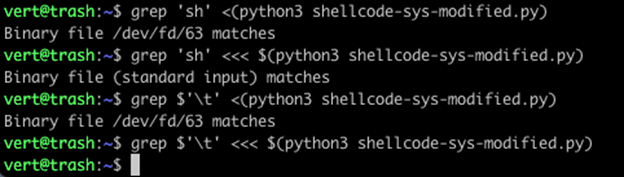
Let’s start with the grep output as it is the easiest to see a change in. When IFS is unset or set to the default, we cannot find our \t (0x09) in the file. However, when we set IFS to nothing, we suddenly get a match on the same result. Next, let’s compare the output in xxd.
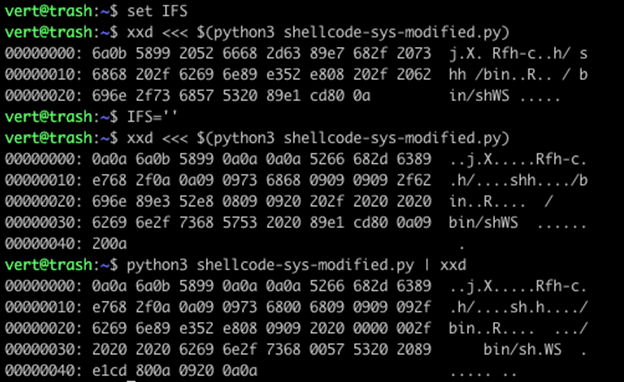
Here we have the output of the same file displayed in xxd, and we have three sets of output. You can see that by changing IFS from default to an empty string, we got back our 0x09 and 0x20 characters. We also appear to have gotten back our 0x0a characters. There is, however, an exception here, which is that in our final output (which is the full byte sequence), we end on a double 0x0a… in the prior example, the duplicate is still stripped. Finally, we lost our 0x00 characters within the string.
These issues are, unfortunately, issues that are unavoidable. The manner in which you execute your commands to generate the data you require will determine the type of output you get. So, in the future, as you’re working through shellcode or any other binary data and want to pass it between programs, if something looks a little wonky, take a step back and evaluate your methods. Sometimes ,the cleanest, most straightforward methods aren’t an option for the techniques you are using, so you might need to adjust what characters you allow in your character set. Hopefully, this helps you on your journey, and you learned something new.
Mastering Security Configuration Management
Master Security Configuration Management with Tripwire's guide on best practices. This resource explores SCM's role in modern cybersecurity, reducing the attack surface, and achieving compliance with regulations. Gain practical insights for using SCM effectively in various environments.

