
As part of a three-part series on incorporating security into the container environment, I've talked all about containers and how to inject security into the pipeline. Let's now discuss tips on how to secure the container stack.
What Do I Mean by "Stack"?
What I’m calling the stack, in this case, refers to all of the layers or components involved with a running container on a Host system. This means securing the platform itself, whether that’s your AWS or Azure environment; securing the Host OS running on that platform, such as Alpine Linux; securing the container technology itself, including the Docker daemon and the Docker container runtime; and all the way down to creating secure container images and Docker files themselves.
The Platform
Securing the platform means ensuring that your AWS or Azure accounts are configured securely. You should ideally use an automated assessment tool that can continually assess your accounts to ensure they are in compliance with best-practices and standards. In the case of AWS, there is a CIS Amazon Web Services Foundations policy available that you can use as a guideline. Verizon’s recent data breach that leaked six million of their customers' personal data online was caused by misconfiguring one of their S3 buckets, causing it to be exposed publicly. This really illustrates the idea that just one simple misconfiguration of your cloud platform can cause catastrophic compromises to the services and data you have hosted there.
The Host OS
While it’s probably not surprising to know you need to secure the Host OS that the containers are running on, it’s critical all the same. To reduce the attack surface as much as possible, your Host OS should be designed for the singular purpose of running containers. It should be lean. That means no services running and no packages installed that aren’t specifically used for running your containers. If you’re using a Traditional Linux OS, this means pairing back services and packages manually, or you could instead use a lightweight Linux OS such as Alpine Linux, which is specifically designed to be minimal, secure, and efficient. There are also purpose-built Linux OSes designed expressly for running containers, such as CoreOS and RancherOS, that may be worth investigating.
Docker
Docker itself is composed of multiple components, and these need to be hardened, as well. CIS has worked with the Docker community to create a benchmark policy that includes best practices for securing both the Docker daemon and container runtime, among other things. There are way too many recommendations in the policy to go through them all, but some examples for the daemon include: making sure you restrict network traffic between containers, making sure that the Docker daemon socket is secured, and using an authorization plugin to configure granular access policies for managing access to the Docker daemon. For the container runtime, this means things like making sure you don’t mount sensitive host system directories on containers, not sharing various host namespaces with containers to keep them isolated, and making sure that containers are running under defined cgroups. You should also use automated security assessment tools to continually assess Docker to ensure that you’ve configured it securely and that it remains secure.
Taking an Immutable Approach
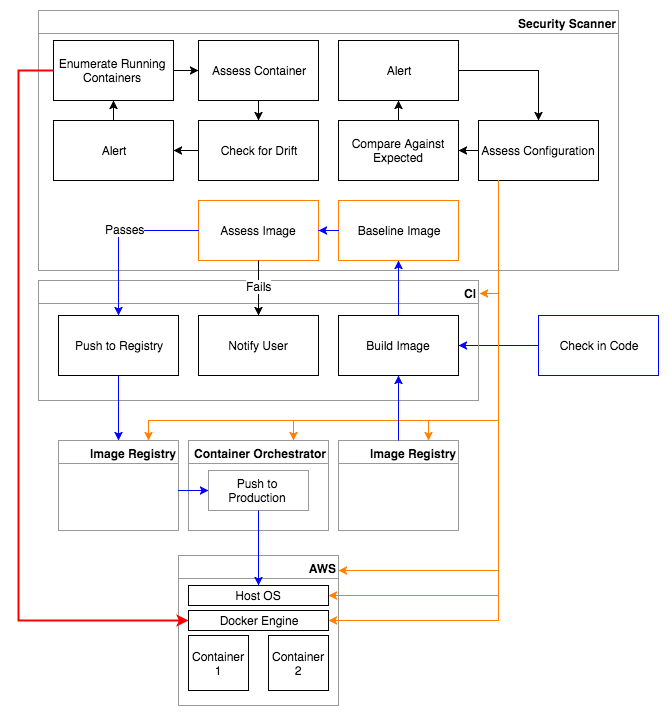
So, how do you fix newly discovered vulnerabilities or misconfigurations in your running containers? In other words, how do I make changes to my containers? Ideally, you would strive to take an immutable approach to your container strategy. This means that you should never make changes directly to your running containers. Don’t change configuration settings, don’t install new packages, and do not upgrade existing packages (even to fix a security vulnerability!). The containers you have running in production should be exactly what you expect them to be based on the images that went through your container pipeline. Any change you need to make to a container in production should involve building a new image, so that the image can make its way back through the pipeline, through the security assessment process, and out into production. You should also consider trying to make your containers read-only. You can pass a read-only flag to your Docker run command to create a read-only container, and you can use the tmpfs flag to mount an empty temporary filesystem for specific directories that may need write access for your application to function properly. It may even be prudent to track the uptime of your running containers in production. Containers that are up for too long have a higher chance of having Drifted, or changed in some way. Change means risk; it means uncertainty. With that in mind, you should consider periodically destroying your running containers and replacing them with new spun up containers to keep them fresh. This way, they only have a limited amount of time to drift before you’re certain they will be reset back to a known fresh state. This also means that any compromise would be short-lived.
Checking for Drift
Once I have running containers in production, I need to continually assess those containers to check for drift even if I’m limiting their uptime by destroying them periodically. So, what do I mean by drift in this case? My running containers are based on images that have already gone through an automated security assessment process. This means I know exactly what vulnerabilities should exist in that container, and I know how compliant that container should be with the standards that I care about. If my container has been running for 30 minutes and now all of a sudden a new vulnerability has appeared or a drop in compliance has occurred, that means something significant has changed in my running container. That’s definitely a cause for concern. I’d also argue that even if you see your compliance score increase or a known vulnerability has disappeared, that too would be a cause for concern. My containers should ideally be immutable. If the container has drifted from my known baseline in some way, I need to investigate why it changed.
Conclusion
I’ve touched on, at a high level, a lot of different components that you need to take into consideration when securing your own container stacks, lifecycles, and pipelines. We touched a bit on assessing container images as a part of the build process, continuously assessing running containers for drift, the importance of your continuous integration tools, container registries, container orchestrators, your cloud platform, Host OSes, and the Docker engine, and we even touched a bit on taking an immutable approach to your container modification strategy. Any one of these pieces could be a blog series in and of themselves, but hopefully now I’ve got you thinking far beyond securing just the containers themselves so that you can start the process (if you haven’t already) of mapping out your own container lifecycles and pipelines so you can begin developing a more comprehensive strategy for securing your containers. You can also find out more about securing the entire container stack, lifecycle and pipeline here. Catch up with the full series here:
Mastering Security Configuration Management
Master Security Configuration Management with Tripwire's guide on best practices. This resource explores SCM's role in modern cybersecurity, reducing the attack surface, and achieving compliance with regulations. Gain practical insights for using SCM effectively in various environments.

