
While the phrase sounds like the stuff of textbook jargon, the term "configuration drift" hides an extremely crucial caution.
Configuration drift is important because it can lead to compliance drift. Compliance drift means that the state of compliance has changed as a result of a configuration that has been changed, which has caused your system to fall out of compliance. When your systems are misconfigured, this small hinge swings a wide door that leads to regulatory scrapes against standards such as PCI DSS, SOX, NERC, and more. The resulting consequences are hefty fines, loss of public trust, and perhaps a few executive seats. No CISO needs that.
What's the solution? Organizations like the Center for Internet Security (CIS) provide guidelines on how to best configure operating systems to minimize the attack surface, and many companies follow them. Similarly, each regulatory body like PCI, NERC and HIPPA have their own guideline on how to securely configure systems to make sure they are compliant. However, the reality of the matter is that while it is easy to deploy a system securely with something like a CIS-hardened image or a compliant gold-image (for PCI/NERC/SOX/etc), maintaining that configuration can be a challenge.
This is where education comes in. To keep the ball rolling, decision-makers need to stay ahead of the problem by learning more about configuration drift and what they can do to prevent it.
What is Configuration Drift?
As time goes on, application owners need to make modifications to their applications and the underlying infrastructure to continuously improve the product they provide to their customers. These customers can be internal to the business or external. As those modifications and changes happen, the configuration of the applications and infrastructure changes. These changes might be benign, or they might take the systems out of a hardened state. This is known as "configuration drift." Depending on the severity of the drift, there could be a significant risk to the organization. Let us examine a few examples of configuration drift to see what the risk would be to the organization.
Configuration Drift Example 1: A New Port
Our company has decided to add this great new innovative section to our application that will enable our customers to use our services in a much more streamlined manner than our competition. To accomplish this, we need to open a new communication port for our proprietary protocol. The business team created a change ticket, opened the port on the servers and firewalls, and the application started working flawlessly. Fast forward six months to the annual security audit, and the auditors ask why this port is open when it is not documented as allowed in the security policy. Is this an acceptable risk to the organization? More often than not, the security team will spend tens of hours trying to trace back what happened to answer this question. In this hypothetical scenario, it is an acceptable risk. The issue here lies in the fact that the auditors were not easily able to determine why the port was open and what the risks and benefits might be. If the security team was tracking the configuration drift and documenting modifications to the known hardened baseline, it would be an easy answer.
Configuration Drift Example 2: The Elevated Privilege
I am an application developer who needs to repeatedly log into a single server. Sometimes, I just need to check something quickly, and sometimes I need to make a small change. I can log in to check things using my regular account without any issues, but when I need to make a production change, I need to check out a special admin credential from the password vault. Needing to check out a credential can become very tedious and time-consuming, especially with all these deadlines we have! Since I have this admin credential, I can just add the "Users" group to the various user rights categories that I need. It's not a big deal, right? It's only one server. I'm not adding it to the entire domain! In this hypothetical scenario, a modification such as this, even to a single server, can pose a significant risk to the organization. The user may have gone through the appropriate change process control for the change the user intended to make initially, but without verification of the exact change the user made, the security team would not know until this particular server was manually audited.
Configuration Drift Example 3: Cloud Storage
Due to many data breaches that have occurred in the past, Amazon has updated its security policy on public access to storage buckets. While creating a new bucket, all public access is blocked by default.
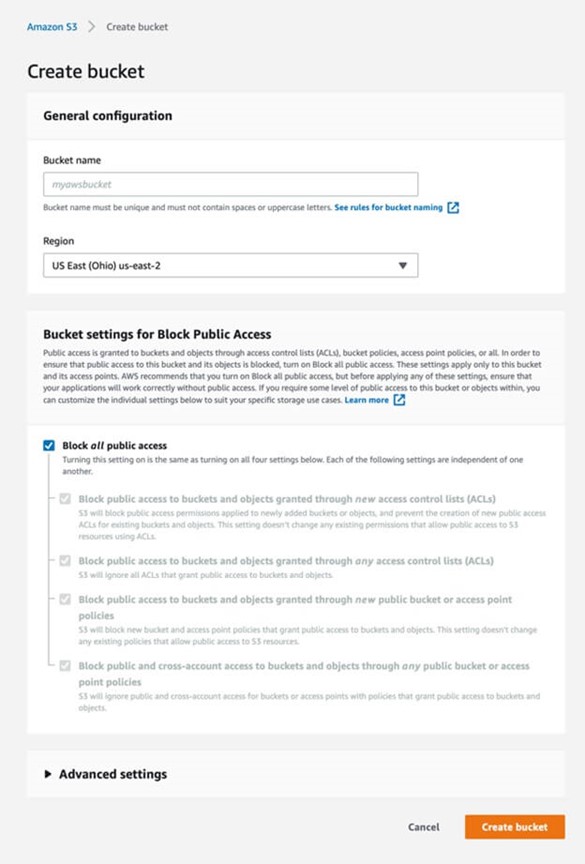
Keeping this default setting would mean:
- Newly added buckets or objects would be private by default, and any new public access ACLs for existing buckets and objects would be restricted.
- All ACLs that grant public access to buckets and objects would be ignored.
- Any new bucket and access point policies that grant public access would be blocked.
- All public and cross-account access for buckets or access points with policies that grant public access to buckets and objects will be blocked.
This is a good security practice, but it might hinder certain IT operations, and therefore, the block setting might be disabled. This could happen from the get-go during the bucket creation or even later by an admin, either for a temporary use case (and later forgotten) or a permanent one, for example, a website might have some flies shared publicly. In addition, a mistake in an automated script could change the bucket access settings, leading to a data breach. Secure configurations and best practices are out there, and they may be initially set, but it is equally important from a security standpoint to monitor for any drift from the approved configurations.
Three main ways to maintain the configuration of a system
There are three main ways to maintain the configuration of a system. Depending on the level of maturity of the security program of a particular organization, they may be doing this at some level or another.
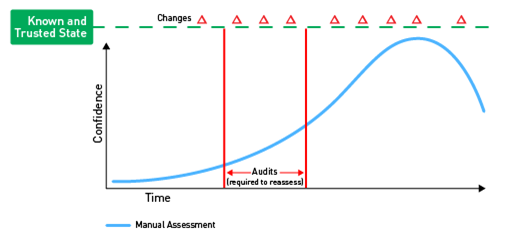
The first level would be to manually monitor the configurations of systems (see Figure A).
This is incredibly time-consuming and therefore is not done on a regular basis, if at all. Systems are either left alone until a compromise is detected, or they need to be upgraded. A subset of these systems may get audited due to compliance regulations. If this is the case, the organization will often try to limit the number of systems within the scope of the audit so there are fewer systems to look at. An auditor will typically ask for substantiation of a subset of the devices within the limited scope to verify its compliance. Only if that subset is found to be non-compliant will there be any significant action taken by the organization.
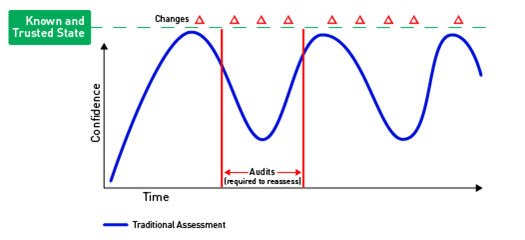
The second level brings in a solution to scan for compliance (see Figure B).
While not as tedious as the first level, this still requires a certain level of interaction to create administrative credentials for the tool to scan with, as well as someone to schedule or run the scans when required and remediate the results. This is typically done once a month or once a quarter to try to get ahead of the audit process. Again, this is commonly limited to systems within a compliance zone. The systems outside of this compliance zone are often left behind and only checked when they are compromised or need to be upgraded. The CIS Critical Security Control #5 recommends that all systems in the organization are provisioned with secure configurations, and therefore that configuration should be maintained on all systems on an ongoing basis even as changes happen.
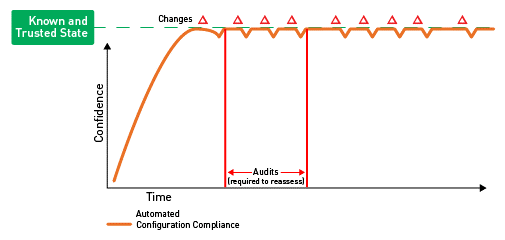
The third and most mature level would be to monitor all systems in a near real-time manner (see Figure C).
This would require that the systems are provisioned with a lightweight agent that can monitor the systems without the need for credentials to log on, or for OS Auditing to be enabled. The agent would need to be deployed to all systems either by embedding it into the images that are deployed or ensuring that it is included in the deployment process of an automated tool, such as Puppet or Chef. Once they are on and monitored, as soon as a change is made that takes the system out of compliance, a remediation process can be initiated. For example, this can be done by automatically creating an incident ticket, sending an e-mail, or alerting the Security Operations Center (SOC) via an alert on the organization's Security Incident and Event Management (SIEM) tool.
To measure the effectiveness of this, CIS recommends tracking the following metrics:
What is the percentage of business systems that are not currently configured with a security configuration that matches the organization's approved configuration standard (by business unit)?
- What is the percentage of business systems whose security configuration is not enforced by the organization's technical configuration management applications (by business unit)?
- What is the percentage of business systems that are not up to date with the latest available operating system software security patches by business unit)?
- What is the percentage of business systems that are not up to date with the latest available business software application security patches (by business unit)?
- What is the percentage of business systems not protected by file integrity assessment software applications (by business unit)?
- What is the percentage of unauthorized or undocumented changes with security impact (by business unit)?
Once these metrics are established, using the continuous improvement process, the security and business teams should work together to increase the percentage of systems that are monitored and then should remediate the systems where configuration drift occurs. Maintaining minimal drift results helps to maintain the secure hardened state of the business systems, which directly assists with the overall risk posture of the organization.
To learn more about how Security Configuration Management will help keep your business secure, click here. Alternatively, you can find out more about Tripwire's SCM solutions here.
Mastering Security Configuration Management
Master Security Configuration Management with Tripwire's guide on best practices. This resource explores SCM's role in modern cybersecurity, reducing the attack surface, and achieving compliance with regulations. Gain practical insights for using SCM effectively in various environments.

